Differentiate Encryption From Compression Using Math
When working with binary blobs such as firmware images, you’ll eventually encounter unknown data. Particularly with regards to firmware, unknown data is usually either compressed or encrypted. Analysis of these two types of data is typically approached in very different manners, so it is useful to be able to distinguish one from the other.
The entropy of data can tell us a lot about the data’s contents. Encrypted data is typically a flat line with no variation, while compressed data will often have at least some variation:


But not all compression algorithms are the same, and some compressed data can be very difficult to visually distinguish from encrypted data:

However, there are a few tests that can be performed to quantify the randomness of data. The two that I have found most useful are chi square distribution and Monte Carlo pi approximation. These tests can be used to measure the randomness of data and are more sensitive to deviations in randomness than a visual entropy analysis.
Chi square distribution is used to determine the deviation of observed results from expected results; for example, determining if the outcomes of 10 coin tosses were acceptably random, or if there were potentially external factors that influenced the results. Substantial deviations from the expected values of truly random data indicate a lack of randomness.
Monte Carlo pi approximation is used to approximate the value of pi from a given set of random (x,y) coordinates; the more unique well distributed data points, the closer the approximation should be to the actual value of pi. Very accurate pi approximations indicate a very random set of data points.
Since each byte in a file can have one of 256 possible values, we would expect a file of random data to have a very even distribution of byte values between 0 and 255 inclusive. We can use the chi square distribution to compare the actual distribution of values to the expected distribution of values and use that comparison to draw conclusions regarding the randomness of data.
Likewise, by interpreting sets of bytes in a file as (x,y) coordinates, we can approximate the value of pi using Monte Carlo approximation. We can then measure the percentage of error in the approximated value of pi to draw conclusions regarding the randomness of data.
Existing tools, such as ent, will perform these calculations for us. The real problem is how to interpret the results; how random is encrypted data vs compressed data? This will depend on both the encryption/compression used, as well as the size of your data set (more data generally means more accurate results). Applying these tests to a (admittedly small) sample of files with varying size which had been put through different compression/encryption algorithms showed the following correlations:
As you can see, gzip has extreme differences between expected and observed data randomness, making it easy to identify. LZMA is much closer to the AES and 3DES encryption results, but still shows significant variations, particularly on the chi square distribution.
Using these tests, we can usually determine if an unknown block of data is encrypted or compressed and proceed with any further analysis accordingly (identification of specific algorithms may also be possible, but much more work would need to be done to determine if such an endeavor is even feasible, and I have my doubts).
The problem with using a tool like ent against a firmware image (or any third-party data for that matter) is that the entire image may not be encrypted/compressed. In a real-world firmware image, there may be multiple blocks of high-entropy data surrounded by lower entropy data.
Here, we see that binwalk has identified one high entropy block of data as LZMA compressed based on a simple signature scan. The second block of high entropy data however, remains unknown:

To prevent the low entropy data in this firmware image from skewing our results, we need to focus only on those blocks of high entropy data and ignore the rest. Since binwalk already identifies high entropy data blocks inside of files, it was a simple matter of adding the chi square and Monte Carlo tests to binwalk, as well as some logic to interpret the results:

If you want to play with it, grab the latest binwalk code from the trunk; this is still very preliminary work, but is showing promise. Of course, the usual cautions apply: don’t trust it blindly, errors will occur and false positives will be encountered. Also, since I’m not a math geek, any feedback from those who actually understand math is appreciated.
The entropy of data can tell us a lot about the data’s contents. Encrypted data is typically a flat line with no variation, while compressed data will often have at least some variation:

Entropy graph of an AES encrypted file
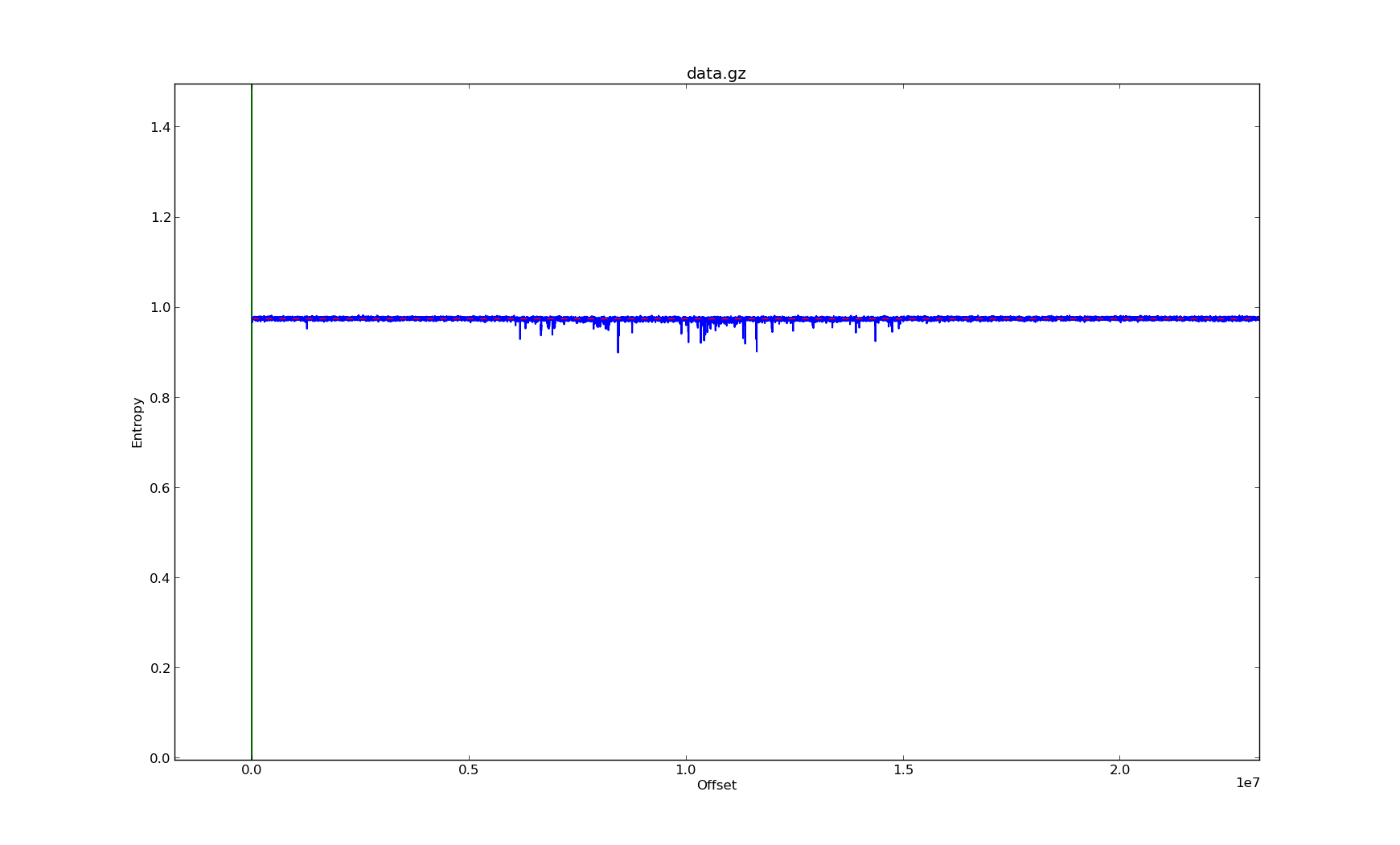
Entropy graph of a gzip compressed file
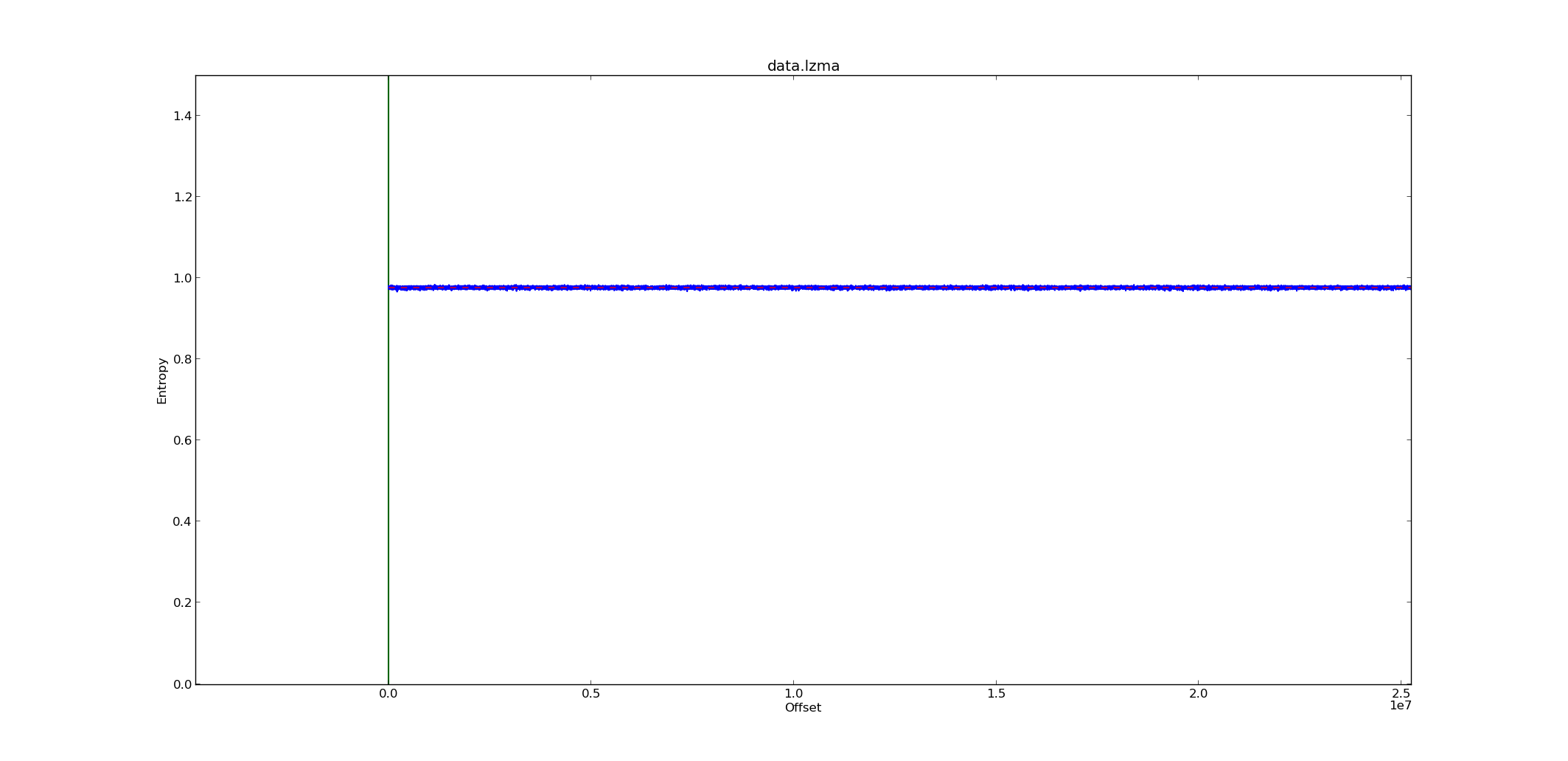
Entropy graph of an LZMA compressed file
Chi square distribution is used to determine the deviation of observed results from expected results; for example, determining if the outcomes of 10 coin tosses were acceptably random, or if there were potentially external factors that influenced the results. Substantial deviations from the expected values of truly random data indicate a lack of randomness.
Monte Carlo pi approximation is used to approximate the value of pi from a given set of random (x,y) coordinates; the more unique well distributed data points, the closer the approximation should be to the actual value of pi. Very accurate pi approximations indicate a very random set of data points.
Since each byte in a file can have one of 256 possible values, we would expect a file of random data to have a very even distribution of byte values between 0 and 255 inclusive. We can use the chi square distribution to compare the actual distribution of values to the expected distribution of values and use that comparison to draw conclusions regarding the randomness of data.
Likewise, by interpreting sets of bytes in a file as (x,y) coordinates, we can approximate the value of pi using Monte Carlo approximation. We can then measure the percentage of error in the approximated value of pi to draw conclusions regarding the randomness of data.
Existing tools, such as ent, will perform these calculations for us. The real problem is how to interpret the results; how random is encrypted data vs compressed data? This will depend on both the encryption/compression used, as well as the size of your data set (more data generally means more accurate results). Applying these tests to a (admittedly small) sample of files with varying size which had been put through different compression/encryption algorithms showed the following correlations:
- Large deviations in the chi square distribution, or large percentages of error in the Monte Carlo approximation are sure signs of compression.
- Very accurate pi calculations (< .01% error) are sure signs of encryption.
- Lower chi values (< 300) with higher pi error (> .03%) are indicative of compression.
- Higher chi values (> 300) with lower pi errors (< .03%) are indicative of encryption.
| Algorithm | Chi Square Distribution | Pi Approximation Error |
|---|---|---|
| None | 15048.60 | .920% |
| AES | 351.68 | .022% |
| 3DES | 357.50 | .029% |
| LZMA | 253.54 | .032% |
| Gzip | 11814.28 | .765% |
Using these tests, we can usually determine if an unknown block of data is encrypted or compressed and proceed with any further analysis accordingly (identification of specific algorithms may also be possible, but much more work would need to be done to determine if such an endeavor is even feasible, and I have my doubts).
The problem with using a tool like ent against a firmware image (or any third-party data for that matter) is that the entire image may not be encrypted/compressed. In a real-world firmware image, there may be multiple blocks of high-entropy data surrounded by lower entropy data.
Here, we see that binwalk has identified one high entropy block of data as LZMA compressed based on a simple signature scan. The second block of high entropy data however, remains unknown:

Binwalk signature scan

Binwalk entropy scan, identifying unknown compression
Here, binwalk has marked both high entropy blocks as compressed data, and the large deviations reported for both tests supports this conclusion. As it turns out, this is correct; after further analysis of the firmware, the second block of data was also found to be LZMA compressed. However, the normal LZMA header had been removed from the data thus thwarting binwalk’s signature scan.DECIMAL HEX ENTROPY ANALYSIS ------------------------------------------------------------------------------------------------------------------- 13312 0x3400 Compressed data, chi square distribution: 35450024.660765 (ideal: 256), monte carlo pi approximation: 2.272365 (38.252134% error) 1441792 0x160000 Compressed data, chi square distribution: 6464693.329427 (ideal: 256), monte carlo pi approximation: 2.348486 (33.771003% error)
If you want to play with it, grab the latest binwalk code from the trunk; this is still very preliminary work, but is showing promise. Of course, the usual cautions apply: don’t trust it blindly, errors will occur and false positives will be encountered. Also, since I’m not a math geek, any feedback from those who actually understand math is appreciated.
No comments:
Post a Comment